ASL Motion-Capture Corpus of American Sign Language
Linguistically annotated corpus of video and motion-capture recordings of American Sign Language...
Linguistically annotated corpus of video and motion-capture recordings of American Sign Language...

Tools for evaluating perception and understanding of facial expressions in ASL animations or videos...
Protocol for accurately and efficiently calibrating motion-capture gloves with deaf participants...

Supplemental data files or videos shared with prior publications from the lab...
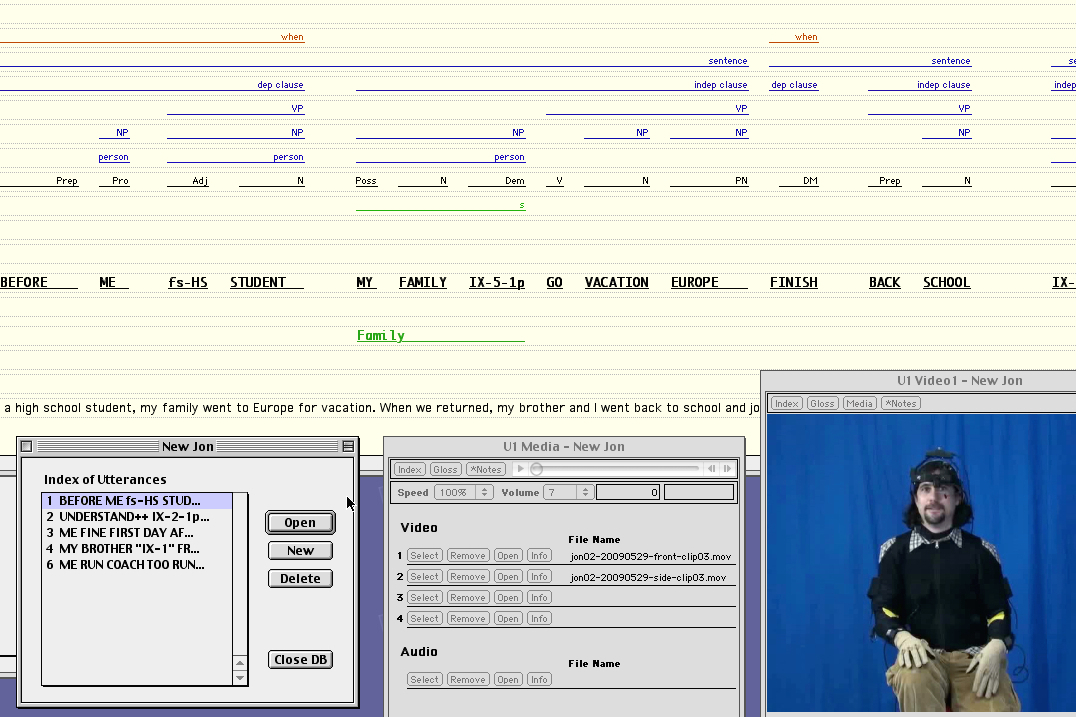
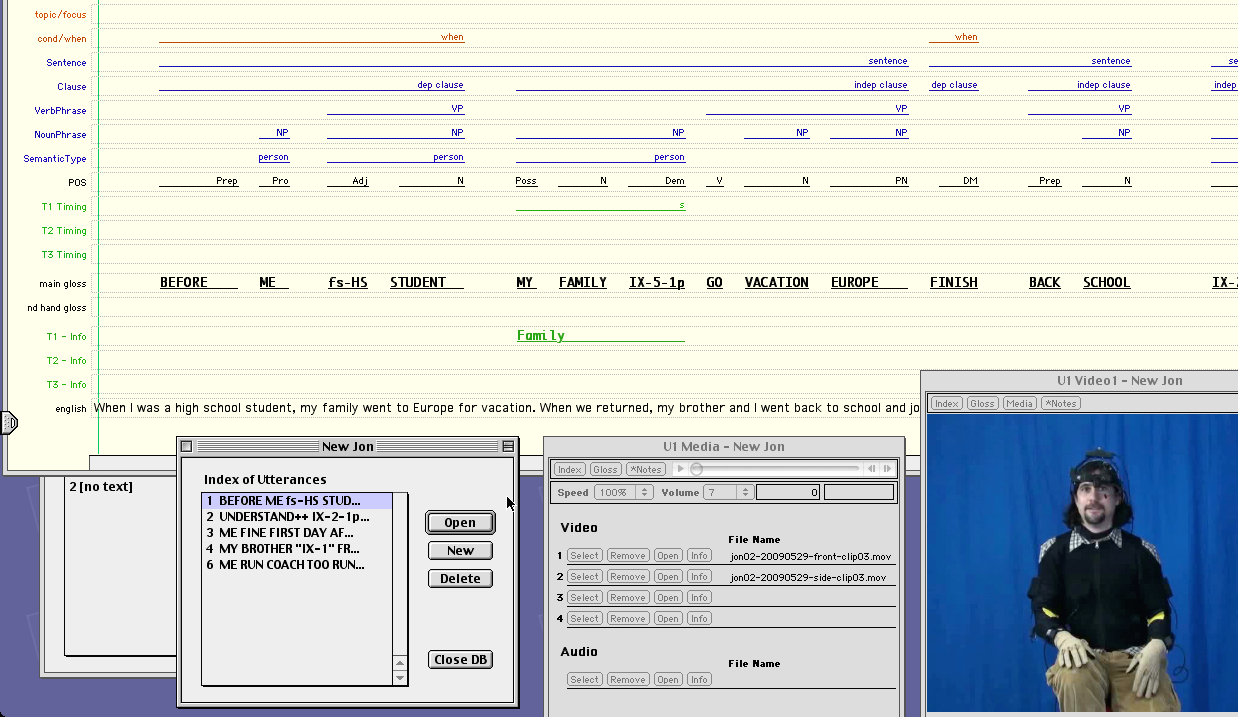
The ASL Motion-Capture Corpus is the result of a multi-year project to collect, annotate, and analyze an ASL motion-capture corpus of multi-sentential discourse. At this time, we are ready to release to the research community the first sub-portion of our corpus that has been checked for quality. The corpus consists of unscripted, single-signer, multi-sentence ASL passages that were the result of various prompting strategies that were designed to encourage signers to use pronominal spatial reference yet minimize the use of classifier predicates. The annotation of the corpus includes glosses for each sign, an English translation of each passage, and details about the establishment and use of pronominal spatial reference points in space. Using this data, we are seeking computational models of the referential use of signing space and of spatially inflected verb forms for use in American Sign Language (ASL) animations, which have accessibility applications for deaf users.
Please send email to matt (dot) huenerfauth (at) rit.edu to inquire about accessing the corpus.
Examples of excerpts of the data contained in the corpus may be available by request. Please send email to matt (dot) huenerfauth (at) rit.edu to request access.
The corpus consists of four types of files, for each story that we have recorded.
This first release of the corpus consists of data collected from 3 signers, a total of 98 stories. Each story is generally 30 seconds to 4 minutes in length.
If you make use of this corpus, please cite the following publication:
Pengfei Lu, Matt Huenerfauth. 2012. "CUNY American Sign Language Motion-Capture Corpus: First Release." Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon, The 8th International Conference on Language Resources and Evaluation (LREC 2012), Istanbul, Turkey.
This material is based upon work supported in part by the National Science Foundation under award number 0746556.
We have developed a collection of stimuli (with accompanying comprehension questions and subjective-evaluation questions) that can be used to evaluate the perception and understanding of facial expressions in ASL animations or videos. The stimuli have been designed as part of our laboratory's on-going research on synthesizing ASL facial expressions such as Topic, Negation, Yes/No Questions, WH-questions, and RH-questions.
Please send email to matt.huenerfauth at rit.edu to inquire about accessing the corpus.
Examples of excerpts of the data contained in the corpus may be available by request. Please send email to matt.huenerfauth at rit.edu to request access.
This material is based upon work supported in part by the National Science Foundation under award number 1065013.
The corpus consists of four types of files, for each story that we have recorded.
This collection consists of 48 stimulus passages, performed by a male signer. Each stimulus is accompanied by four comprehension questions. Each comprehension question is performed by both a male signer (the same one performing the stimulus passage) and a female signer.
If you make use of this collection, please cite the following publication:
Matt Huenerfauth, Hernisa Kacorri. 2014. "Release of Experimental Stimuli and Questions for Evaluating Facial Expressions in Animations of American Sign Language." Proceedings of the 6th Workshop on the Representation and Processing of Sign Languages: Beyond the Manual Channel, The 9th International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland.
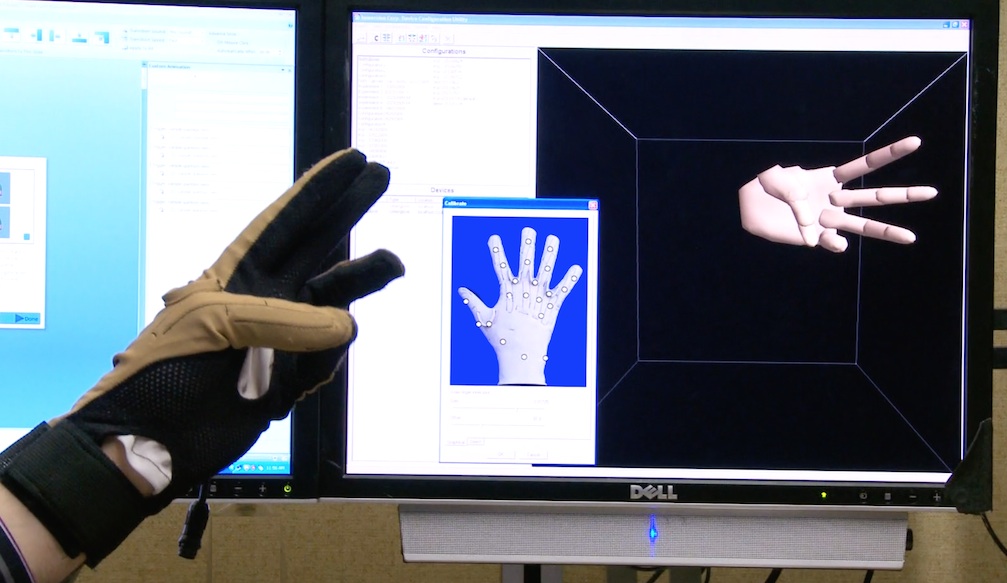
We have created a website demonstrating how we calibrate the cybergloves for experiments at the lab, using a protocol we developed. It is discussed in a paper presented at the ASSETS 2009 conference and in a journal article in TACCESS in 2010.
This protocol is designed to be an efficient approach to producing a high-quality human calibration of the gloves, and it has been designed to be accessible to deaf research participants.
The accuracy of the calibrations produced using this protocol has been experimentally measured and shown to be more accurate than the standard automatic calibration software that accompanies the gloves.
We have created a website with videos and other materials for researchers who wish to replicate our calibration process.
If you make use of this collection, please cite the following publication:
Matt Huenerfauth and Pengfei Lu. 2010. "Accurate and Accessible Motion-Capture Glove Calibration for Sign Language Data Collection." ACM Transactions on Accessible Compututing. Volume 3, Issue 1, Article 2 (September 2010), 32 pages. DOI=10.1145/1838562.1838564 http://doi.acm.org/10.1145/1838562.1838564
In this section, we provide a listing of supplemental data files or videos that have been shared as part of prior publications from the laboratory.
This page contains supplementary files for: Larwan Berke, Matt Huenerfauth, and Kasmira Patel. 2019. Design and Psychometric Evaluation of American Sign Language Translations of Usability Questionnaires. ACM Transactions on Accessible Computing 12, 2, Article 6 (May 2019), 43 pages. https://doi.org/10.1145/3314205
This page contains supplementary files for: Sushant Kafle, Matt Huenerfauth. 2018. A Corpus for Modeling Word Importance in Spoken Dialogue Transcripts. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan.
This page contains supplementary files for: Stephanie Ludi, Matt Huenerfauth, Vicki Hanson, Nidhi Palan and Paula Garcia. 2018. Teaching Inclusive Thinking to Undergraduate Students in Computing Programs. In Proceedings of the 2018 ACM SIGCSE Technical Symposium on Computer Science Education. ACM, New York, NY, USA.
This page contains supplementary files for: Matt Huenerfauth, Kasmira Patel, and Larwan Berke. 2017. Design and Psychometric Evaluation of an American Sign Language Translation of the System Usability Scale. In Proceedings of the 19th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS '17). ACM, New York, NY, USA, 175-184. DOI: https://doi.org/10.1145/3132525.3132540
This page contains supplementary files for: Larwan Berke, Christopher Caulfield, and Matt Huenerfauth. 2017. Deaf and Hard-of-Hearing Perspectives on Imperfect Automatic Speech Recognition for Captioning One-on-One Meetings. In Proceedings of the 19th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS '17). ACM, New York, NY, USA, 155-164. DOI: https://doi.org/10.1145/3132525.3132541
This page contains supplementary files for: Khaled Albusays, Stephanie Ludi, and Matt Huenerfauth. 2017. Interviews and Observation of Blind Software Developers at Work to Understand Code Navigation Challenges. In Proceedings of the 19th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS '17). ACM, New York, NY, USA, 91-100. DOI: https://doi.org/10.1145/3132525.3132550
This page contains supplementary files for: Sushant Kafle and Matt Huenerfauth. 2017. Evaluating the Usability of Automatically Generated Captions for People who are Deaf or Hard of Hearing. In Proceedings of the 19th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS '17). ACM, New York, NY, USA, 165-174. DOI: https://doi.org/10.1145/3132525.3132542
This page contains supplementary files for: Hernisa Kacorri, Matt Huenerfauth, Sarah Ebling, Kasmira Patel, Kellie Menzies, Mackenzie Willard. 2017. Regression Analysis of Demographic and Technology Experience Factors Influencing Acceptance of Sign Language Animation. ACM Transactions on Accessible Computing. 10, 1, Article 3 (April 2017), 33 pages. DOI: https://doi.org/10.1145/3046787
This page contains supplementary files for: Matt Huenerfauth, Elaine Gale, Brian Penly, Sree Pillutla, Mackenzie Willard, Dhananjai Hariharan. 2017. Evaluation of Language Feedback Methods for Student Videos of American Sign Language. ACM Transactions on Accessible Computing. 10, 1, Article 2 (April 2017), 30 pages. DOI: https://doi.org/10.1145/3046788
This page contains supplementary files for: Matt Huenerfauth, Pengfei Lu, Hernisa Kacorri. 2015. Synthesizing and Evaluating Animations of American Sign Language Verbs Modeled from Motion-Capture Data. Proceedings of the 6th Workshop on Speech and Language Processing for Assistive Technologies (SLPAT), INTERSPEECH 2015, Dresden, Germany.
This page contains supplementary files for: Hernisa Kacorri, Matt Huenerfauth. 2015. Evaluating a Dynamic Time Warping Based Scoring Algorithm for Facial Expressions in ASL Animations. Proceedings of the 6th Workshop on Speech and Language Processing for Assistive Technologies (SLPAT), INTERSPEECH 2015, Dresden, Germany.
This page contains supplementary files for: Hernisa Kacorri, Matt Huenerfauth, Sarah Ebling, Kasmira Patel, Mackenzie Willard. 2015. Demographic and Experiential Factors Influencing Acceptance of Sign Language Animation by Deaf Users. In Proceedings of the 17th Annual SIGACCESS Conference on Computers and Accessibility (ASSETS'16). Lisbon, Portugal. New York: ACM Press.
This page contains supplementary files for: Matt Huenerfauth, Elaine Gale, Brian Penly, Mackenzie Willard, Dhananjai Hariharan. 2015. Comparing Methods of Displaying Language Feedback for Student Videos of American Sign Language. In Proceedings of the 17th Annual SIGACCESS Conference on Computers and Accessibility (ASSETS'16). Lisbon, Portugal. New York: ACM Press.
This page contains supplementary files for: Matt Huenerfauth, Hernisa Kacorri. 2014. Release of Experimental Stimuli and Questions for Evaluating Facial Expressions in Animations of American Sign Language. Proceedings of the 6th Workshop on the Representation and Processing of Sign Languages: Beyond the Manual Channel, The 9th International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland.
This page contains supplementary files for: Hernisa Kacorri, Matt Huenerfauth. 2014. Implementation and evaluation of animation controls sufficient for conveying ASL facial expressions. In Proceedings of The 16th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS'14). Rochester, New York, USA. New York: ACM Press.
This page contains supplementary files for: Pengfei Lu, Matt Huenerfauth. 2012. Learning a Vector-Based Model of American Sign Language Inflecting Verbs from Motion-Capture Data. Proceedings of the Third Workshop on Speech and Language Processing for Assistive Technologies (SLPAT), The 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2012), Montreal, Quebec, Canada. East Stroudsburg, PA: Association for Computational Linguistics.
This page contains supplementary files for: Pengfei Lu, Matt Huenerfauth. 2011. Data-Driven Synthesis of Spatially Inflected Verbs for American Sign Language Animation. ACM Transactions on Accessible Computing. Volume 4 Issue 1, November 2011. New York: ACM Press. 29 pages.
This page contains supplementary files for: Pengfei Lu, Matt Huenerfauth. 2011. Synthesizing American Sign Language Spatially Inflected Verbs from Motion-Capture Data. The Second International Workshop on Sign Language Translation and Avatar Technology (SLTAT), The 13th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS 2011), Dundee, Scotland, United Kingdom.
This page contains supplementary files for: Matt Huenerfauth, Pengfei Lu. 2010. Modeling and Synthesizing Spatially Inflected Verbs for American Sign Language Animations. In Proceedings of The 12th International ACM SIGACCESS Conference on Computers and Accessibility (ASSETS 2010), Orlando, Florida, USA. New York: ACM Press.
This page contains supplementary files for: Matt Huenerfauth. 2009. A Linguistically Motivated Model for Speed and Pausing in Animations of American Sign Language. ACM Transactions on Accessible Computing (journal). Volume 2, Number 2, Article 9.
This page contains supplementary files for: Matt Huenerfauth, Liming Zhou, Erdan Gu and Jan Allbeck. 2008. "Evaluation of American Sign Language Generation by Native ASL Signers." ACM Transactions on Accessible Computing (journal). Volume 1, Number 1, Article 3.